텍스트 마이닝 프로젝트를 위한 첫 단계인 데이터 수집 단계에서 python으로 크롤링을 진행했습니다.
beautifulsoup과 request 조합으로 크롤링을 할 수 있지만
약 3-4만개의 리뷰를 여러 페이지에서 크롤링 할 수 있도록 자동화하기 위해서
selenium 모듈을 사용했어요 !
*) selenium: 웹페이지 테스트 자동화용 모듈로, 개발/테스트용 드라이버(웹브라우저)를 사용하여 실제 사용자가 사용하는 것처럼 동작시킬 수 있음 (id, password 입력과 같이 검색창에 검색 키 전달, 버튼 클릭 etc..)
*) 실습전 확인사항
1. selenium 모듈 설치 (아나콘다 navigator - environments - selenium 검색)
2. 크롬 드라이버 다운로드 ( https://chromedriver.chromium.org/downloads )
- 필요한 모듈 및 패키지 라이브러리 import
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
- 제품명 크롤링
selenium에서는 driver 객체에 특정 element를 가져오기 위한 함수들을 제공하고 있습니다.
- find_element_by_tag_name
- find_element_by_class_name
- find_element_by_id
- find_element_by_xpath
- find_element_by_css_selector
위와 같은 함수에 찾고싶은 element의 tag나 class, id, xpath, css selector을 전달하면
해당되는 element를 반환하는데요,
element의 xpath, selector같은 것들은 개발자 도구를 들어가서 확인하실 수 있습니다.
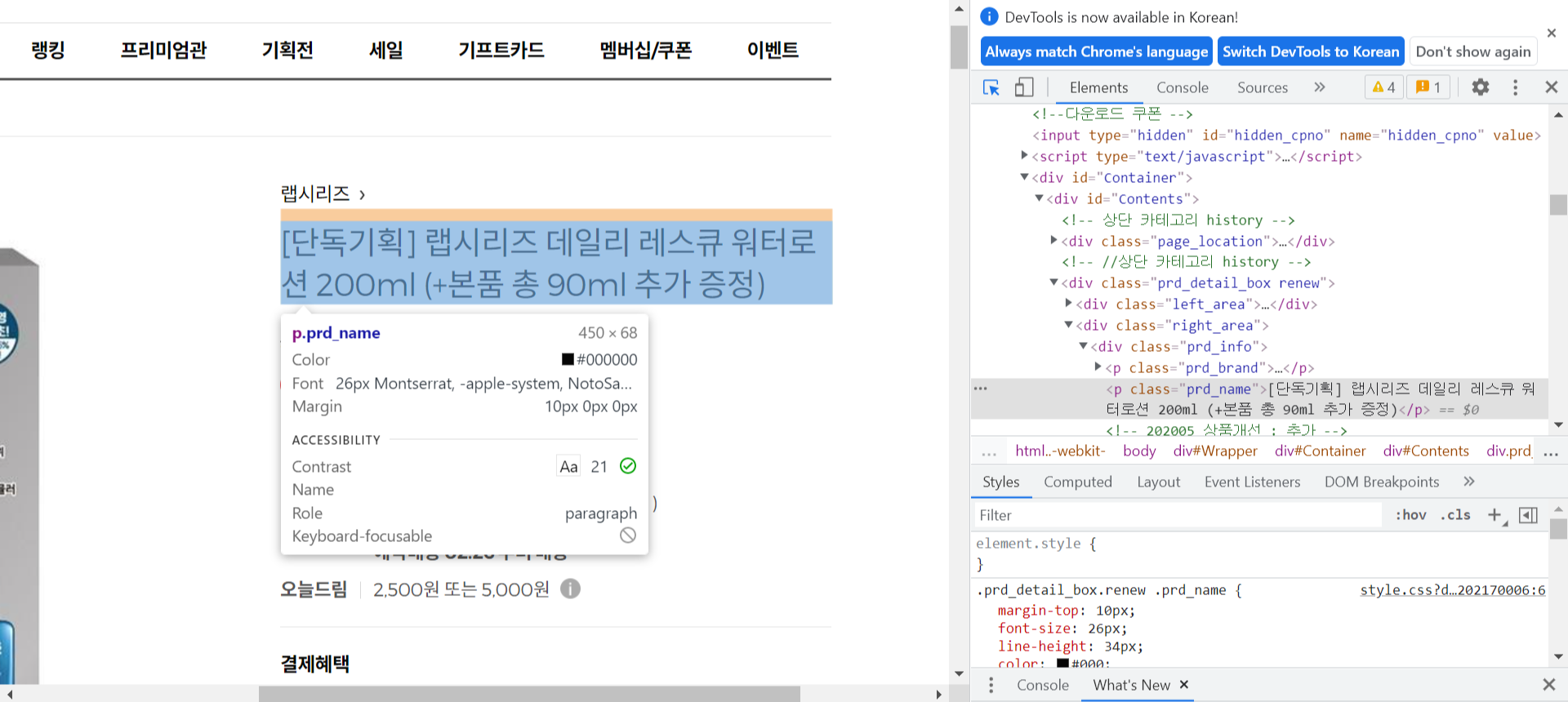

- 개발자 도구의 좌측 상단 커서모양 버튼을 누르고 긁어오고자 하는 element를 클릭
- html에서 표시되는 element 위에서 우클릭 - Copy - 원하는 Copy 내용 선택
- 함수 입력값으로 사용 (ex: Copy XPath를 선택 - find_element_by_xpath() 의 입력값으로 전달)
#크롬 드라이버 설치 경로
chrome_driver = '설치 디렉토리 경로 입력'
#드라이버 객체 생성
driver = webdriver.Chrome(chrome_driver)
#get함수에 이동하고자 할 사이트 전달
url = 'https://www.oliveyoung.co.kr/store/goods/getGoodsDetail.do?goodsNo=A000000161782&dispCatNo=100000100010008&trackingCd=Cat100000100010008_MID#'
driver.get(url)
prod_name = driver.find_element_by_xpath('//*[@id="Contents"]/div[2]/div[2]/div/p[2]')
print(prod_name.text)
driver.close()
element의 앞뒤 태그가 제거되고 안에 있는 text, 즉 제품명이 출력되는 것을 볼 수 있습니다.
- 리뷰 텍스트 크롤링
리뷰는 url 변수에 저장된 주소로 이동한 뒤, [리뷰]라는 버튼을 클릭해야 볼 수 있습니다.
따라서 driver로 브라우저를 연 후에 버튼을 클릭하는 이벤트를 수행하도록 해줍니다.
클릭도 마찬가지로 클릭할 element의 xpath를 복사해서 review_box 변수에 저장해놓고
review_box에서 .click() 메소드를 호출해줍니다.
driver = webdriver.Chrome(chrome_driver)
driver.get('https://www.oliveyoung.co.kr/store/goods/getGoodsDetail.do?goodsNo=A000000161782&dispCatNo=100000100010008&trackingCd=Cat100000100010008_MID#')
review_box = driver.find_element_by_xpath('//*[@id="reviewInfo"]/a')
review_box.click()
그런데 앞선 제품명을 크롤링 했을 때와는 달리, 리뷰 텍스트에 해당하는 줄글을 크롤링하려고 하면
None으로 아무것도 크롤링 되지 않습니다.
왜냐하면 브라우저를 이용하면 요청이 한 번에 오는 게 아니기 때문에
원하는 element가 아직 로딩되지 않은 것일 수도 있기 때문입니다 !
따라서 WebDriverWait 객체를 이용해 해당 element가 로딩되기까지 대기하고
페이지에 담긴 소스를 그대로 사용해봅시다.
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, '#gdasList > li:nth-child(1) > div.review_cont > div.txt_inner')))- WebDriverWait(드라이버 객체인 driver, 최대 10초간 대기)
- .until(EC.presence_of_element_located): element가 로딩될 때까지 대기
- By.CSS_SELECTOR: css selector를 이용해서 element 찾을 것
- 어떤 element를 찾을지: 개발자 도구의 해당 element에서 우클릭-Copy-Copy selector
최대 10초동안 우리가 원하는 element가 로딩될 때까지 기다렸으므로
페이지의 html 소스를 src 변수에 저장하고 BeautifulSoup 객체를 만들어줍니다.
src = driver.page_source
soup2 = BeautifulSoup(src)
driver.close()
그런 다음 soup 객체에서 리뷰 텍스트에 해당하는 element를 가져와야 하는데,
이 때는 CSS를 이용해서 tag를 찾기 위해 .select_one() 함수를 사용합니다.
개발자 도구의 element에 우클릭 - Copy - Copy selector 을 함수의 입력값으로 전달합니다.
review = soup2.select_one('#gdasList > li:nth-child(1) > div.review_cont > div.txt_inner')
review.get_text()
select_one으로 가져온 값에서 앞뒤를 감싸는 태그는 제거하고
가운데의 value, 즉 text에 해당하는 부분만 가져오기 위해 .get_text() 함수를 사용합니다.
driver = webdriver.Chrome(chrome_driver)
driver.get(url)
review_box = driver.find_element_by_xpath('//*[@id="reviewInfo"]/a')
review_box.click()
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, '#gdasList > li:nth-child(1) > div.review_cont > div.txt_inner')))
src = driver.page_source
soup2 = BeautifulSoup(src)
driver.close()
review = soup2.select_one('#gdasList > li:nth-child(1) > div.review_cont > div.txt_inner')
review.get_text()
(전체코드)